Trong thế giới kỹ thuật số ngày nay, nơi thông tin liên tục được cập nhật và đổi mới, việc đảm bảo website của bạn được hiển thị hiệu quả trên các công cụ tìm kiếm là điều tối quan trọng. Tại vietnamesecoupon.net, chúng tôi hiểu rằng để độc giả có thể tiếp cận những nội dung chất lượng cao về SEO, thiết kế website và tên miền, việc hiểu rõ về “Crawling” và vai trò của “Web Crawler” là bước khởi đầu không thể thiếu. Bài viết này sẽ đi sâu vào khái niệm Crawling, cách Web Crawler hoạt động và vì sao chúng lại có tầm ảnh hưởng lớn đến chiến lược SEO tổng thể của bạn.
Crawling là gì? Khái niệm cơ bản về thu thập dữ liệu web
Crawling, hay còn gọi là quá trình thu thập thông tin, là bước khởi đầu trong việc các công cụ tìm kiếm khám phá và lập chỉ mục nội dung trên Internet. Hãy hình dung, các công cụ tìm kiếm lớn như Google không hề ngồi yên chờ đợi chúng ta gửi từng trang web để được tìm thấy. Thay vào đó, họ sử dụng một đội quân robot tự động, được gọi là “Web Crawler”, “Spiders”, hay “Bot Crawler” (phổ biến nhất là Googlebot của Google), để liên tục lùng sục khắp các ngõ ngách của web. Nhiệm vụ của chúng là tìm kiếm mọi nội dung mới, hoặc nội dung đã được cập nhật, từ các trang web, hình ảnh, video, tài liệu PDF, cho đến bất kỳ định dạng nào khác có sẵn trên mạng lưới toàn cầu.
Điều thú vị là, mặc dù nội dung có thể vô cùng đa dạng, nhưng hầu hết chúng đều được các trình thu thập thông tin này phát hiện thông qua các liên kết. Mỗi khi một Web Crawler ghé thăm một trang, nó sẽ đọc mã nguồn, xác định tất cả các liên kết (hyperlink) trên trang đó và thêm chúng vào một danh sách các địa chỉ cần khám phá tiếp theo. Cứ như vậy, các bot này dần dần xây dựng một bản đồ rộng lớn về Internet, đảm bảo rằng gần như mọi thông tin công khai đều có thể được tìm thấy và xử lý.
Tầm quan trọng của Web Crawler trong chiến lược SEO hiệu quả
Bạn có tự hỏi tại sao Web Crawler lại là một phần không thể thiếu của SEO không? Đơn giản mà nói, nếu không có Web Crawler, sẽ không có SEO. SEO (Search Engine Optimization) là tập hợp các hoạt động nhằm tối ưu hóa để website của bạn đạt được thứ hạng cao hơn trong kết quả tìm kiếm cho các từ khóa mục tiêu. Vị trí càng cao, cơ hội tiếp cận khách hàng tiềm năng càng lớn.
Web Crawler đóng vai trò cực kỳ quan trọng trong quá trình lập chỉ mục (indexing) – một bước sau Crawling, nơi thông tin thu thập được sẽ được phân tích, sắp xếp và lưu trữ vào cơ sở dữ liệu của công cụ tìm kiếm. Nếu một trang web không được Web Crawler thu thập dữ liệu, nó sẽ không thể được lập chỉ mục, và do đó, không thể hiển thị trong kết quả tìm kiếm. Điều này có nghĩa là, dù nội dung của bạn có xuất sắc đến mấy, dù bạn có nhập chính xác từng chữ vào thanh tìm kiếm, trang web đó vẫn sẽ vô hình với người dùng.
Để trang web của bạn xuất hiện trên Google, nó phải trải qua ba giai đoạn chính: Crawling (thu thập), Indexing (lập chỉ mục) và Ranking (xếp hạng). Web Crawler là cánh cổng đầu tiên, là mắt xích không thể thiếu để toàn bộ quy trình SEO diễn ra. Hiểu và tối ưu hóa khả năng thu thập dữ liệu của bot sẽ giúp bạn đảm bảo nội dung của mình được phát hiện nhanh chóng, chính xác, từ đó mở ra cơ hội cạnh tranh trên bảng xếp hạng tìm kiếm.
 Tầm quan trọng của Web Crawler trong SEO
Tầm quan trọng của Web Crawler trong SEO
Web Crawler hoạt động như thế nào? Quy trình khám phá nội dung
Quy trình hoạt động của một Web Crawler không hề ngẫu nhiên mà được thiết kế một cách có hệ thống để tối ưu hiệu quả khám phá và cập nhật nội dung. Mọi chuyện thường bắt đầu khi một Web Crawler tiếp cận một trang web bằng cách tải xuống tệp robot.txt của trang đó. Tệp này giống như một bản hướng dẫn, cho bot biết những khu vực nào trên website được phép hoặc không được phép thu thập thông tin, và thường bao gồm sitemaps – sơ đồ trang web liệt kê tất cả các URL mà công cụ tìm kiếm có thể và nên thu thập dữ liệu.
Sau khi đọc robot.txt và nắm rõ các “luật chơi”, bot crawler sẽ bắt đầu từ một tập hợp các trang web “hạt giống” (seed URLs) đã biết và tin cậy. Từ đó, nó sẽ theo dõi tất cả các hyperlink từ những trang này đến các trang khác, khám phá một mạng lưới liên kết rộng lớn. Mỗi khi một URL mới được phát hiện, nó sẽ được thêm vào một hàng đợi để được thu thập và lập chỉ mục sau này. Quá trình này giúp Web Crawler lập chỉ mục mọi trang web được kết nối với những trang khác, tạo nên một cơ sở dữ liệu khổng lồ về thông tin trên Internet.
Tuy nhiên, Web Crawler không thu thập thông tin của toàn bộ Internet một cách mù quáng hay liên tục. Các trang web luôn thay đổi và cập nhật nội dung, nhưng bot phải ưu tiên tài nguyên của mình. Chúng sẽ quyết định tầm quan trọng của mỗi trang web dựa trên nhiều yếu tố, bao gồm số lượng backlinks trỏ về trang đó, số lượt xem trang (traffic), và thậm chí cả uy tín thương hiệu của website. Dựa vào những yếu tố này, các bot sẽ xác định trang nào cần thu thập thông tin, thứ tự ưu tiên, và tần suất quay lại để cập nhật dữ liệu. Điều này còn được gọi là “Crawl Budget”, tức là lượng tài nguyên mà công cụ tìm kiếm dành ra để thu thập dữ liệu trên một website nhất định.
Các Web Crawler phổ biến hiện nay: Ai đang quét Internet?
Không chỉ Google mới có bot của riêng mình. Các công cụ tìm kiếm lớn khác cũng sở hữu các trình thu thập thông tin web chuyên biệt để phục vụ cho mục đích lập chỉ mục của họ. Việc nhận biết các bot này có thể giúp bạn hiểu rõ hơn về cách các công cụ tìm kiếm khác nhau khám phá nội dung của bạn.
Googlebot là trình thu thập thông tin chính của Google, và nó không chỉ là một bot duy nhất. Thực tế, Googlebot bao gồm nhiều biến thể khác nhau để thu thập dữ liệu từ các nền tảng và định dạng khác nhau. Có Googlebot dành cho máy tính để bàn (desktop) và Googlebot dành cho thiết bị di động (mobile), đảm bảo rằng Google có thể hiểu được trải thái website của bạn trên cả hai môi trường này. Bên cạnh đó, còn có các bot bổ sung như Googlebot Images để lập chỉ mục hình ảnh, Googlebot Videos cho nội dung video, Googlebot News cho các bài báo tin tức, và AdsBot chuyên thu thập thông tin cho hệ thống quảng cáo của Google. Sự đa dạng này cho thấy mức độ chi tiết mà Google đầu tư vào việc thu thập dữ liệu.
Ngoài Google, còn có nhiều bot crawler khác từ các công cụ tìm kiếm khác trên thế giới:
- DuckDuckBot là trình thu thập thông tin của công cụ tìm kiếm DuckDuckGo, nổi tiếng với việc tập trung vào quyền riêng tư của người dùng.
- Yandex Bot được sử dụng bởi Yandex, công cụ tìm kiếm hàng đầu tại Nga.
- Baiduspider là bot của Baidu, công cụ tìm kiếm phổ biến nhất tại Trung Quốc.
- Yahoo! Slurp là trình thu thập thông tin chính của Yahoo!, mặc dù Yahoo! hiện nay thường sử dụng kết quả từ Bing.
 Các Web Crawler đang hoạt động trên Internet
Các Web Crawler đang hoạt động trên Internet
Việc biết các bot này không chỉ mang tính học thuật mà còn có ý nghĩa thực tiễn trong SEO. Ví dụ, nếu bạn nhận thấy một lượng lớn truy cập từ một bot cụ thể, bạn có thể phân tích hành vi của nó để điều chỉnh chiến lược tối ưu hóa cho công cụ tìm kiếm tương ứng.
Phân biệt Web Crawler và Web Scraper: Hiểu đúng để tối ưu SEO
Trong thế giới thu thập dữ liệu web, hai thuật ngữ “Web Crawler” và “Web Scraper” thường bị nhầm lẫn hoặc sử dụng thay thế cho nhau. Mặc dù chúng có liên quan và đều liên quan đến việc trích xuất thông tin từ web, nhưng mục đích và phương thức hoạt động của chúng lại có những khác biệt cơ bản mà mọi chuyên gia SEO cần nắm rõ.
Web Crawler, như chúng ta đã tìm hiểu, là chương trình tự động của công cụ tìm kiếm với mục đích khám phá và thu thập tất cả các nội dung mới hoặc cập nhật trên Internet. Chúng “bò” từ liên kết này sang liên kết khác, mục tiêu là xây dựng một bản đồ toàn diện của web để lập chỉ mục. Web Crawler không chỉ dừng lại ở việc thu thập thông tin của một trang mà còn truy cập sâu vào các liên kết bên trong để tiếp tục quá trình khám phá. Mục đích cuối cùng của Web Crawler là phục vụ công cụ tìm kiếm, giúp nó hiểu được cấu trúc và nội dung của Internet.
Ngược lại, Web Scraper là một công cụ hoặc tập hợp các công cụ được thiết kế để trích xuất một tập hợp dữ liệu cụ thể từ một hoặc nhiều trang web. Mục tiêu của Web Scraper thường rất cụ thể, ví dụ như thu thập giá sản phẩm từ các trang thương mại điện tử, danh sách email, thông tin liên hệ, hoặc các bài đánh giá sản phẩm. Scraper tập trung vào việc “cạo” hoặc “gặt hái” các dữ liệu cụ thể theo nhu cầu của người dùng, không quan tâm đến việc lập chỉ mục toàn bộ website hay khám phá các liên kết khác.
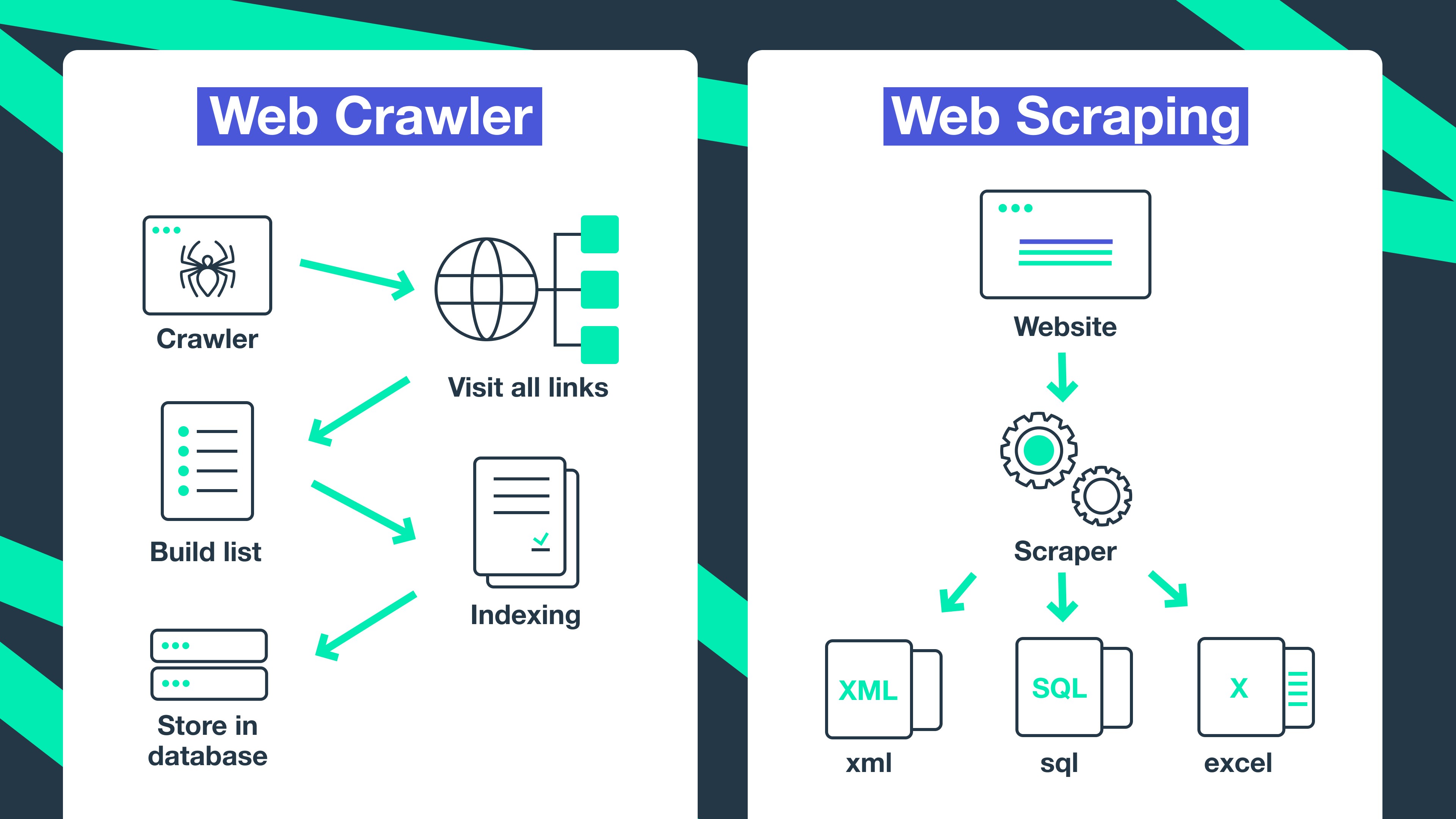 Phân biệt Web Crawling và Web Scraping
Phân biệt Web Crawling và Web Scraping
Những điểm khác biệt chính có thể tóm gọn như sau:
- Mục đích: Web Crawler phục vụ công cụ tìm kiếm để lập chỉ mục. Web Scraper phục vụ người dùng để trích xuất dữ liệu cụ thể.
- Phạm vi: Crawler thu thập toàn bộ nội dung và theo các liên kết. Scraper tập trung vào tập hợp dữ liệu cụ thể trên một trang hoặc một số trang nhất định.
- Phương thức: Crawling thường chỉ được thực hiện bằng các công cụ tự động (bot crawler). Scraping có thể thực hiện thủ công hoặc bằng các công cụ tự động.
Hiểu rõ sự khác biệt này giúp bạn không chỉ tránh nhầm lẫn mà còn có thể định hình chiến lược SEO của mình tốt hơn. Bạn cần tối ưu hóa website của mình để Web Crawler có thể dễ dàng khám phá và lập chỉ mục, trong khi đó, bạn có thể cần bảo vệ dữ liệu của mình khỏi Web Scraper không mong muốn nếu chúng vi phạm chính sách của bạn.
Kết luận
Crawling và Web Crawler là những khái niệm cơ bản nhưng vô cùng mạnh mẽ, định hình cách chúng ta tương tác với thông tin trên Internet. Đối với những ai đang dấn thân vào lĩnh vực SEO, việc nắm vững cách thức hoạt động của các trình thu thập thông tin này không chỉ là kiến thức nền tảng mà còn là chìa khóa để tối ưu hóa website hiệu quả.
Tại vietnamesecoupon.net, chúng tôi luôn nỗ lực mang đến những kiến thức sâu rộng, cập nhật nhất về SEO, thiết kế website và tên miền, giúp độc giả tự tin hơn trên hành trình phát triển website của mình. Bằng cách đảm bảo website của bạn thân thiện với Web Crawler, bạn đang đặt nền móng vững chắc cho khả năng hiển thị, tăng cường lưu lượng truy cập và cuối cùng là đạt được mục tiêu kinh doanh. Hãy nhớ rằng, một website được crawl tốt là một website có cơ hội lớn để tỏa sáng trên các công cụ tìm kiếm.