Trong kỷ nguyên số, thông tin thay đổi chóng mặt, nhưng lịch sử web lại ẩn chứa vô vàn giá trị. Bạn có bao giờ tò mò muốn biết một trang web đã trông như thế nào cách đây 5, 10 năm, hay muốn khôi phục lại nội dung quan trọng đã mất? Với Wayback Machine, “cỗ máy thời gian” của Internet, mọi thứ đều có thể. Tại vietnamesecoupon.net, chúng tôi luôn nỗ lực mang đến những kiến thức chuyên sâu về SEO, thiết kế website và tên miền, và hôm nay, chúng ta sẽ cùng khám phá một công cụ độc đáo, không chỉ giúp thỏa mãn trí tò mò mà còn là trợ thủ đắc lực cho các chuyên gia số.
Wayback Machine là gì? Hành trình lưu giữ di sản số của Internet Archive
Wayback Machine không chỉ đơn thuần là một website; nó là một kho lưu trữ kỹ thuật số khổng lồ, là trái tim của Internet Archive – một tổ chức phi lợi nhuận có trụ sở tại San Francisco, California. Được Brewster Kahle và Bruce Gilliat sáng lập vào năm 1996, Internet Archive đặt ra sứ mệnh cao cả: “Cung cấp quyền truy cập phổ quát vào mọi tri thức” (“Universal Access to All Knowledge”). Trong bối cảnh World Wide Web đang bùng nổ và các trang web liên tục thay đổi, biến mất, họ nhận ra sự cần thiết phải bảo tồn “tài sản” số này cho các thế hệ tương lai.
Ra mắt công chúng vào năm 2001, Wayback Machine đã trở thành hiện thực hóa tầm nhìn đó, cho phép người dùng “quay ngược thời gian” để xem các phiên bản cũ của hàng tỷ trang web. Tên gọi “Wayback Machine” được lấy cảm hứng từ cỗ máy thời gian hư cấu cùng tên trong bộ phim hoạt hình “Rocky and Bullwinkle” thập niên 1960, nơi các nhân vật Mr. Peabody và Sherman du hành về quá khứ để chứng kiến các sự kiện lịch sử. Đến tháng 10 năm 2025, Wayback Machine đã tự hào lưu trữ hơn 1 nghìn tỷ trang web và hơn 99 petabyte dữ liệu, một con số thực sự choáng ngợp, minh chứng cho quy mô và tầm quan trọng của dự án này. Đây không chỉ là một công cụ hoài niệm mà còn là một di sản kỹ thuật số vô giá, phục vụ các nhà nghiên cứu, sử học, học giả và công chúng toàn cầu.
Cơ chế hoạt động của Wayback Machine: Bí mật đằng sau cỗ máy thời gian Internet
Vậy làm thế nào để Wayback Machine có thể lưu trữ và tái hiện lại lịch sử của Internet một cách kỳ diệu như vậy? Mọi thứ bắt đầu từ một quy trình thu thập dữ liệu (crawling) tinh vi, tương tự như cách các công cụ tìm kiếm lớn như Google hoạt động. Wayback Machine sử dụng các “robot” tự động để quét và thu thập dữ liệu từ hàng tỷ trang web công khai trên khắp World Wide Web. Khi một robot quét một trang, nó sẽ tạo một “ảnh chụp nhanh” (snapshot) của trang web đó tại thời điểm cụ thể, bao gồm nội dung văn bản, hình ảnh, mã nguồn HTML và các tập tin liên quan (nếu có thể). Những ảnh chụp nhanh này sau đó được lưu trữ trên một hệ thống máy chủ khổng lồ của Internet Archive.
Tuy nhiên, quá trình này không phải lúc nào cũng hoàn hảo. Có một số thách thức kỹ thuật mà Wayback Machine phải đối mặt. Các trang web hiện đại thường sử dụng nhiều JavaScript và nội dung động (dynamic content), vốn được tạo ra hoặc thay đổi sau khi trang được tải lần đầu. Điều này khiến việc chụp ảnh chính xác toàn bộ giao diện và chức năng của trang trở nên khó khăn. Do đó, một số ảnh chụp nhanh có thể bị thiếu hình ảnh, CSS bị lỗi, hoặc các chức năng tương tác không hoạt động. Hơn nữa, Wayback Machine cũng tuân thủ các chỉ thị trong tệp robots.txt của website – một tệp văn bản mà chủ sở hữu trang web sử dụng để yêu cầu các công cụ tìm kiếm không thu thập dữ liệu từ một số phần nhất định của trang. Nếu một trang web chặn các crawler của Internet Archive thông qua robots.txt, nội dung đó sẽ không được lưu trữ. Ngoài ra, các trang cần mật khẩu để truy cập, các trang đứng sau tường phí (paywall), hoặc các trang trên máy chủ riêng tư cũng nằm ngoài khả năng thu thập của Wayback Machine. Mặc dù vậy, với hàng trăm tỷ trang đã được lưu, đây vẫn là một nỗ lực phi thường trong việc bảo tồn di sản số.
Hướng dẫn sử dụng Wayback Machine hiệu quả: Khám phá quá khứ website trong tầm tay
Việc sử dụng Wayback Machine khá đơn giản và trực quan, cho phép bất kỳ ai cũng có thể trở thành “nhà thám hiểm thời gian” trên Internet. Dưới đây là hai phương pháp chính để bạn có thể khám phá các phiên bản cũ của một trang web:
Phương pháp 1: Lưu trang web từ thanh địa chỉ trình duyệt
Phương pháp này rất tiện lợi khi bạn đang duyệt một trang web và muốn nhanh chóng tạo một bản sao lưu tức thời.
- Mở trang web: Đầu tiên, hãy mở trang web mà bạn muốn lưu trữ trong trình duyệt của mình.
- Chỉnh sửa URL: Di chuyển con trỏ chuột đến đầu thanh địa chỉ, ngay trước URL hiện tại của trang đó.
- Thêm tiền tố: Gõ hoặc dán
web.archive.org/save/ngay trước URL của trang web. Ví dụ, nếu URL làhttps://example.com, bạn sẽ sửa thànhweb.archive.org/save/https://example.com. - Nhấn Enter: Sau khi thêm tiền tố, nhấn phím “Enter”.
- Chờ đợi: Wayback Machine sẽ bắt đầu quá trình lưu trữ trang. Một thông báo xác nhận sẽ xuất hiện khi quá trình hoàn tất, cho biết trang đã được lưu thành công và cung cấp liên kết đến bản sao lưu.
Phương pháp 2: Sử dụng trực tiếp trang lưu trữ của Wayback Machine
Đây là cách phổ biến nhất để tìm kiếm các phiên bản đã lưu trữ của một trang web.
- Sao chép URL: Truy cập trang web bạn quan tâm và sao chép URL của nó.
- Truy cập Wayback Machine: Mở trình duyệt và đi đến trang chủ của Wayback Machine tại
archive.org. - Dán URL: Ở giữa trang chủ, bạn sẽ thấy một ô tìm kiếm lớn. Dán URL bạn đã sao chép vào ô này.
- Nhấn “Browse History”: Nhấp vào nút “Browse History” (hoặc “Save Page Now” nếu bạn muốn lưu một phiên bản mới).
- Khám phá lịch sử: Sau khi nhập URL và nhấn tìm kiếm, bạn sẽ được đưa đến một trang hiển thị lịch sử lưu trữ của trang web đó dưới dạng một lịch (calendar). Các vòng tròn màu xanh lam hoặc xanh lá cây trên lịch biểu thị những ngày mà Wayback Machine đã chụp ảnh nhanh của trang.
- Màu xanh lam: Thường biểu thị một ảnh chụp nhanh tiêu chuẩn.
- Màu xanh lá cây: Có thể chỉ ra một bản lưu được tạo thông qua tính năng “Save Page Now” hoặc một bản lưu do người dùng đóng góp.
- Chọn ngày: Nhấp vào một vòng tròn trên lịch, sau đó chọn một mốc thời gian cụ thể (ví dụ: năm, tháng, ngày) để xem phiên bản của trang web tại thời điểm đó.
- Lưu ý quan trọng: Khi xem các phiên bản cũ, hãy nhớ rằng không phải tất cả các yếu tố đều có thể hoạt động hoàn hảo. Các liên kết đến tài nguyên bên ngoài (như quảng cáo, font chữ, hoặc script từ máy chủ khác) có thể đã không còn tồn tại hoặc không được lưu trữ, dẫn đến giao diện không hoàn chỉnh hoặc một số chức năng bị hỏng.
 Giao diện Wayback Machine giúp người dùng khám phá lịch sử website
Giao diện Wayback Machine giúp người dùng khám phá lịch sử website
Wayback Machine cũng đã phát triển thành tiện ích mở rộng chính thức cho trình duyệt Google Chrome, giúp người dùng dễ dàng lưu trữ trang web và khắc phục lỗi 404 bằng cách tự động tìm kiếm bản sao lưu trữ. [cite: bài viết gốc] Tuy nhiên, dù tiện lợi, việc nhập chính xác địa chỉ trang web là cực kỳ quan trọng, nếu không, công cụ này có thể không tìm thấy dữ liệu bạn cần.
Ứng dụng đột phá của Wayback Machine trong SEO và phát triển website
Đối với các chuyên gia SEO, nhà thiết kế website và quản trị viên, Wayback Machine không chỉ là một công cụ khám phá lịch sử mà còn là một kho báu dữ liệu chiến lược. Khả năng “du hành thời gian” trên Internet mở ra nhiều cơ hội quý giá để phân tích, tối ưu hóa và phát triển website hiệu quả.
1. Phục hồi nội dung và dữ liệu bị mất
Một trong những ứng dụng quan trọng nhất của Wayback Machine là khả năng phục hồi dữ liệu. Nếu một trang web gặp sự cố, bị tấn công, hoặc nội dung bị xóa nhầm mà không có bản sao lưu, bạn có thể tìm lại phiên bản trước đó thông qua Wayback Machine. [cite: bài viết gốc, 5, 1] Điều này đặc biệt hữu ích cho các SEOer khi một phần nội dung quan trọng – ví dụ, một bài viết từng xếp hạng cao – bị mất. Bạn có thể khôi phục lại văn bản, hình ảnh, thậm chí cả mã HTML của trang, giúp lấy lại lưu lượng truy cập và thứ hạng đã mất. Việc có thể truy cập mã nguồn cũ cũng giúp bạn kiểm tra các meta tag, tiêu đề, cấu trúc URL hay các yếu tố SEO kỹ thuật khác đã thay đổi. [cite: bài viết gốc, 5, 2, 5]
2. Nghiên cứu đối thủ cạnh tranh chuyên sâu
Wayback Machine là một công cụ tuyệt vời để thực hiện “phân tích đối thủ cạnh tranh ngược” (competitor teardowns). Thay vì chỉ xem chiến lược hiện tại của đối thủ, bạn có thể quay ngược thời gian để xem họ đã làm gì cách đây 2-3 năm, cách họ phát triển nội dung, thay đổi thiết kế, hoặc triển khai các chiến dịch SEO.
- Phân tích nội dung: Xem đối thủ đã tăng độ dài bài viết như thế nào, khi nào họ thêm mục lục (on-page SEO), hay thay đổi các từ khóa mục tiêu.
- Thay đổi thiết kế và cấu trúc: Quan sát sự tiến hóa của giao diện, trải nghiệm người dùng, và cấu trúc website để hiểu những quyết định thiết kế nào đã mang lại hiệu quả. [cite: bài viết gốc]
- Chiến lược backlink: Phát hiện các liên kết cũ mà đối thủ từng có nhưng giờ đã bị mất, mở ra cơ hội để bạn “kéo” các liên kết đó về cho mình.
3. Đánh giá lịch sử tên miền trước khi mua
Khi mua một tên miền đã có lịch sử, việc kiểm tra quá khứ của nó là cực kỳ quan trọng để tránh những rủi ro SEO tiềm ẩn. Một tên miền từng bị Google phạt vì các hoạt động “black hat SEO” (spam, nội dung kém chất lượng) có thể ảnh hưởng tiêu cực đến khả năng xếp hạng của website mới. Wayback Machine cho phép bạn xem các phiên bản cũ của tên miền, phát hiện bất kỳ dấu hiệu đáng ngờ nào về nội dung, chủ đề hoặc liên kết. Điều này giúp bạn đưa ra quyết định sáng suốt, đảm bảo tên miền có một lịch sử “sạch” và tiềm năng SEO tốt.
4. Phân tích tác động của thuật toán và khắc phục sự cố SEO
Nếu website của bạn đột ngột mất thứ hạng hoặc lưu lượng truy cập sau một bản cập nhật thuật toán của Google hoặc sau khi thực hiện các thay đổi trên trang, Wayback Machine có thể giúp bạn tìm ra nguyên nhân. Bằng cách so sánh các ảnh chụp nhanh của trang trước và sau khi sự cố xảy ra, bạn có thể xác định chính xác những thay đổi về nội dung, cấu trúc, hoặc yếu tố kỹ thuật nào có thể đã gây ra vấn đề. Ví dụ, bạn có thể kiểm tra:
- Các thay đổi về văn bản, tiêu đề, hoặc mô tả meta.
- Việc xóa bỏ các plugin tối ưu hóa.
- Thay đổi trong tệp
robots.txtgây chặn crawler. - Sự biến mất của các liên kết nội bộ quan trọng.
Công cụ này giúp bạn khoanh vùng và khắc phục các vấn đề SEO kỹ thuật một cách nhanh chóng và chính xác.
5. Kiểm tra và tối ưu hóa cấu trúc website
Wayback Machine cũng là một nguồn tài nguyên tuyệt vời để theo dõi sự phát triển của cấu trúc website. Bạn có thể xem cách một trang web đã thay đổi từ giao diện, sơ đồ trang (sitemap) đến cách sắp xếp nội dung và hệ thống phân cấp. [cite: bài viết gốc, 5, 2] Đối với các dự án di chuyển website hoặc tái cấu trúc, công cụ này giúp bạn kiểm tra xem các trang quan trọng có bị “chôn vùi” sâu hơn trong menu điều hướng hay không, điều có thể ảnh hưởng đến khả năng thu thập dữ liệu của công cụ tìm kiếm và trải nghiệm người dùng. Khả năng xem lại các phiên bản cũ của robots.txt cũng giúp đảm bảo rằng các thay đổi không vô tình chặn các phần quan trọng của trang web khỏi việc được lập chỉ mục.
6. Chứng minh quyền sở hữu nội dung và bằng chứng pháp lý
Trong một số trường hợp, Wayback Machine có thể được sử dụng để chứng minh quyền sở hữu nội dung hoặc thời điểm một thông tin cụ thể được đăng tải. [cite: bài viết gốc] Bằng cách lưu trữ một phiên bản trang web vào một thời điểm cụ thể, nó có thể đóng vai trò như một loại “chứng cứ pháp lý” về sự tồn tại của nội dung tại thời điểm đó. Điều này có thể hữu ích trong các tranh chấp về bản quyền hoặc bằng sáng chế. Tuy nhiên, cần lưu ý rằng độ tin cậy của Wayback Machine như bằng chứng pháp lý có những hạn chế nhất định, và cần phải tuân thủ các quy định nghiêm ngặt về xác thực bằng chứng kỹ thuật số.
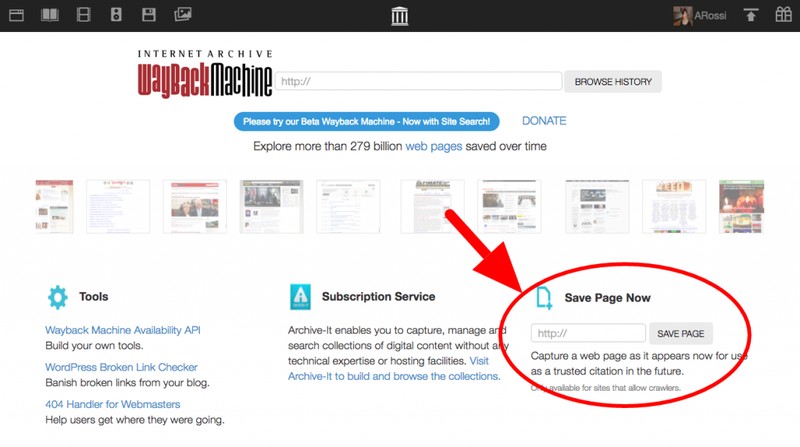 Sử dụng ô "Save Page Now" để lưu trữ một phiên bản trang web hiện tại
Sử dụng ô "Save Page Now" để lưu trữ một phiên bản trang web hiện tại
Những hạn chế và thách thức pháp lý của Wayback Machine
Mặc dù Wayback Machine là một công cụ vô cùng giá trị, nó cũng đi kèm với những hạn chế và gây ra các tranh cãi nhất định, đặc biệt liên quan đến quyền riêng tư và bản quyền. [cite: bài viết gốc, 3, 1]
1. Vấn đề bản quyền và tranh chấp pháp lý
Một trong những thách thức lớn nhất của Wayback Machine là việc lưu trữ và sao chép nội dung website mà không có sự đồng ý rõ ràng từ chủ sở hữu có thể bị coi là vi phạm luật bản quyền ở một số khu vực pháp lý. [cite: bài viết gốc, 3, 1] Internet Archive đã đối mặt với nhiều vụ kiện liên quan đến bản quyền và Đạo luật Bản quyền Thiên niên kỷ Kỹ thuật số (DMCA). Ví dụ, các vụ kiện như Healthcare Advocates và Suzanne Shell đã nêu bật vấn đề này, buộc Internet Archive phải gỡ bỏ nội dung theo yêu cầu của chủ sở hữu nếu có tệp robots.txt hoặc yêu cầu gỡ bỏ trực tiếp.
Gần đây, làn sóng các công ty AI sử dụng dữ liệu web để đào tạo mô hình ngôn ngữ lớn đã khiến nhiều trang tin tức lớn như The New York Times, The Guardian và Reddit bắt đầu chặn Wayback Machine thông qua tệp robots.txt của họ. Họ lo ngại rằng việc lưu trữ nội dung của họ trên Wayback Machine có thể trở thành “cửa sau” để các công ty AI tiếp cận và sử dụng nội dung mà không được cấp phép, gây ảnh hưởng đến doanh thu và quyền sở hữu trí tuệ của họ. Điều này đặt ra một câu hỏi lớn về cân bằng giữa quyền lợi của người tạo nội dung và mục tiêu bảo tồn tri thức phổ quát.
2. Hạn chế kỹ thuật và độ chính xác của dữ liệu
Như đã đề cập, Wayback Machine không thể lưu trữ mọi trang web một cách hoàn hảo. Nội dung động (JavaScript, Flash), các biểu mẫu tương tác, hoặc các trang có yêu cầu đăng nhập thường không được chụp lại đầy đủ hoặc không hiển thị chính xác. Điều này có thể dẫn đến các ảnh chụp nhanh bị “hỏng”, thiếu hình ảnh, CSS bị lỗi, hoặc chức năng không hoạt động, khiến việc phân tích hoặc sử dụng làm bằng chứng gặp khó khăn.
Ngoài ra, tần suất thu thập dữ liệu của Wayback Machine là không thể đoán trước và phụ thuộc vào mức độ phổ biến của trang web. Một trang tin tức lớn có thể được lưu trữ nhiều lần trong ngày, nhưng một trang web nhỏ hơn có thể chỉ được lưu trữ vài tháng một lần, hoặc thậm chí không bao giờ. Điều này tạo ra những “khoảng trống” trong lịch sử, khiến việc tìm kiếm thông tin tại một thời điểm chính xác trở nên khó khăn.
3. Vấn đề riêng tư và thông tin cá nhân
Việc lưu trữ các phiên bản cũ của trang web cũng có thể gây ra lo ngại về quyền riêng tư. Các trang web công khai có thể chứa thông tin cá nhân như số điện thoại, địa chỉ email, hoặc hình ảnh cá nhân đã bị xóa khỏi trang web gốc nhưng vẫn còn tồn tại trong kho lưu trữ của Wayback Machine. Mặc dù Internet Archive có chính sách gỡ bỏ nội dung theo yêu cầu hợp lệ, nhưng quá trình này đòi hỏi người dùng phải chủ động liên hệ và có thể mất thời gian.
 Các thách thức pháp lý và tranh cãi xung quanh hoạt động lưu trữ của Wayback Machine
Các thách thức pháp lý và tranh cãi xung quanh hoạt động lưu trữ của Wayback Machine
Wayback Machine: Nền tảng cho bảo tồn kỹ thuật số và tri thức nhân loại
Dù có những hạn chế nhất định, vai trò của Wayback Machine và Internet Archive trong việc bảo tồn kỹ thuật số là không thể phủ nhận và ngày càng trở nên quan trọng. Công cụ này là một nền tảng vững chắc cho việc bảo tồn lịch sử Internet, không chỉ để hoài niệm mà còn vì những mục đích thiết thực và cao cả hơn.
1. Tài nguyên vô giá cho nghiên cứu học thuật và lịch sử
Wayback Machine là một kho tài liệu quý giá cho các nhà nghiên cứu, sử gia, và học giả trên toàn thế giới. [cite: bài viết gốc, 2, 1, 5] Nó cho phép họ theo dõi sự phát triển của các trang web lớn như Google, Facebook, hoặc Amazon qua từng năm, từ giao diện đến cấu trúc và tính năng. [cite: bài viết gốc] Các nhà sử học có thể nghiên cứu các sự kiện chính trị, xã hội thông qua các bản tin tức được lưu trữ, trong khi các nhà nghiên cứu công nghệ có thể phân tích xu hướng thiết kế web, sự thay đổi của ngôn ngữ lập trình, hoặc sự ra đời của các ứng dụng mới. Nó cung cấp một cái nhìn sâu sắc về cách thông tin được trình bày và tiếp nhận trong quá khứ, góp phần vào việc xây dựng một bức tranh toàn diện về lịch sử kỹ thuật số của nhân loại.
2. Hỗ trợ báo chí và kiểm chứng thông tin
Trong lĩnh vực báo chí, Wayback Machine đóng vai trò quan trọng trong việc kiểm chứng thông tin và theo dõi sự thay đổi của các bản tin. Các nhà báo có thể sử dụng nó để tìm lại các bài viết, tuyên bố, hoặc dữ liệu đã bị xóa hoặc chỉnh sửa khỏi trang gốc. Điều này giúp đảm bảo tính minh bạch, trách nhiệm giải trình, và ngăn chặn việc thao túng thông tin. Khi một nguồn tin bị thay đổi sau khi xuất bản, khả năng truy cập phiên bản cũ trên Wayback Machine có thể trở thành bằng chứng quan trọng, giúp duy trì sự trung thực trong môi trường truyền thông số.
3. Bảo tồn di sản văn hóa và tri thức cộng đồng
Internet không chỉ là một công cụ, mà còn là một phần không thể thiếu của văn hóa hiện đại. Rất nhiều tài liệu quý giá, dự án nghệ thuật, diễn đàn cộng đồng, và các trang web cá nhân độc đáo đã từng tồn tại và góp phần vào di sản văn hóa số của chúng ta. Khi các trang web này biến mất do đóng cửa, hết hạn tên miền, hoặc thay đổi chủ sở hữu, một phần của lịch sử và tri thức cũng có nguy cơ bị thất lạc vĩnh viễn. Wayback Machine, cùng với Internet Archive, hoạt động như một “thư viện kỹ thuật số” để lưu giữ những “hiện vật” số này, đảm bảo rằng chúng vẫn có thể được truy cập và nghiên cứu bởi các thế hệ sau.
4. Thách thức trong bối cảnh web hiện đại
Tuy nhiên, với sự phức tạp ngày càng tăng của web hiện đại – bao gồm các ứng dụng web tiến bộ (PWA), nội dung tương tác mạnh mẽ với API, và sự phổ biến của mạng xã hội – việc lưu trữ toàn diện và chính xác ngày càng trở nên thách thức. Internet Archive liên tục phải thích nghi và phát triển công nghệ để theo kịp tốc độ thay đổi của Internet, đảm bảo